

算法
选择最有效的算法⬆️
这个可以通过SIMULIA CST Studio Suite®轻松完成,因为在前端提供了许多数值算法。
使用先进的工作流程和模型耦合策略,例如SAM,场源耦合等。
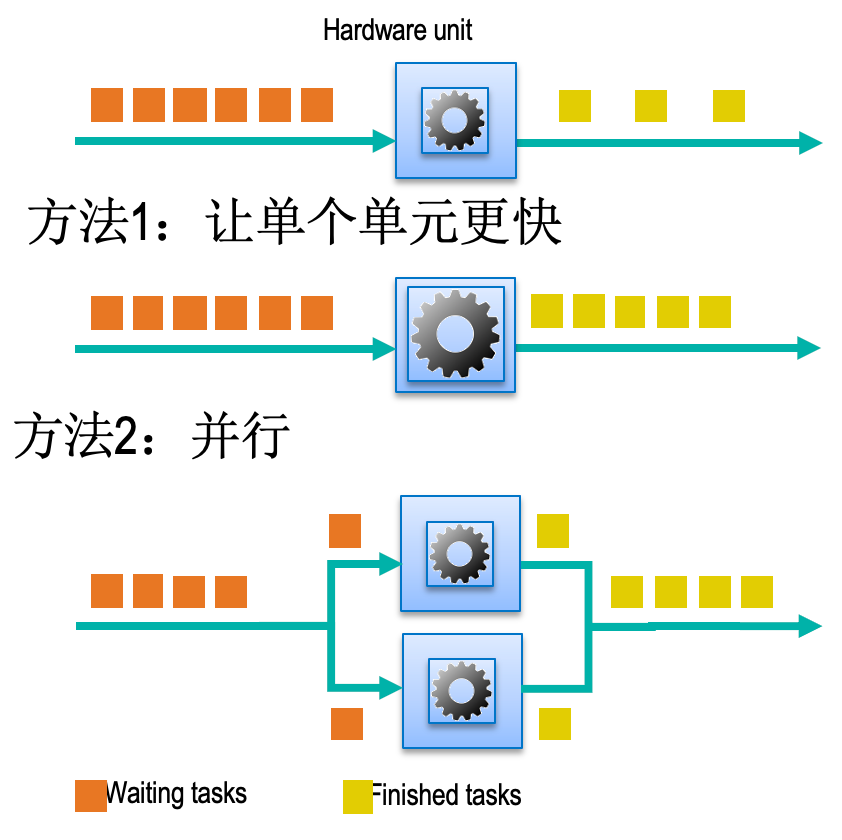
硬件
当出现瓶颈的时候使用更好(更快)的硬件

CPU 多线程

GPU 计算
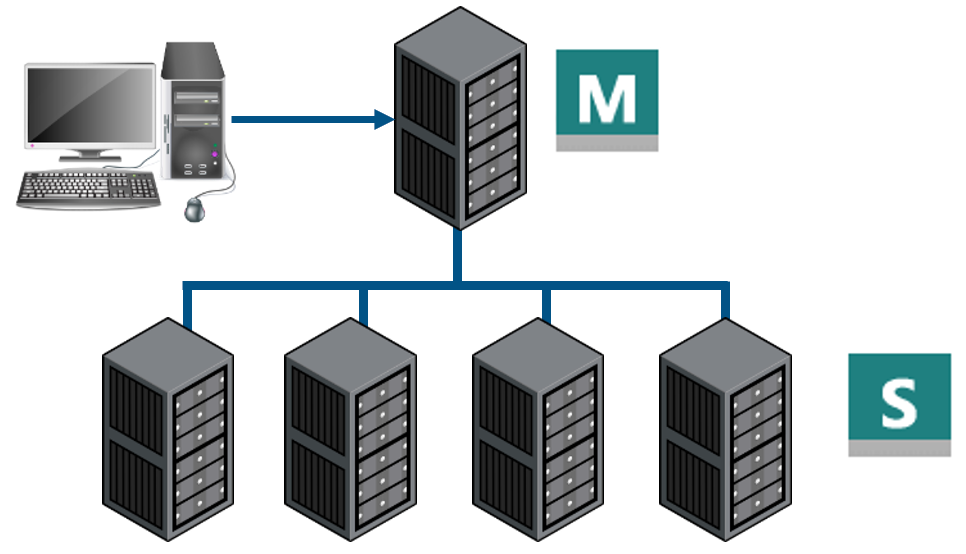
分布式计算
MPI 计算





















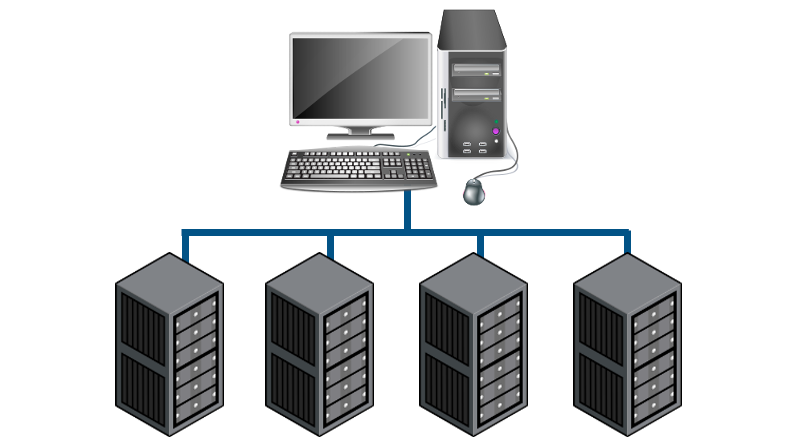
传统DC设置
将CST项目的副本传送到所有计算节点
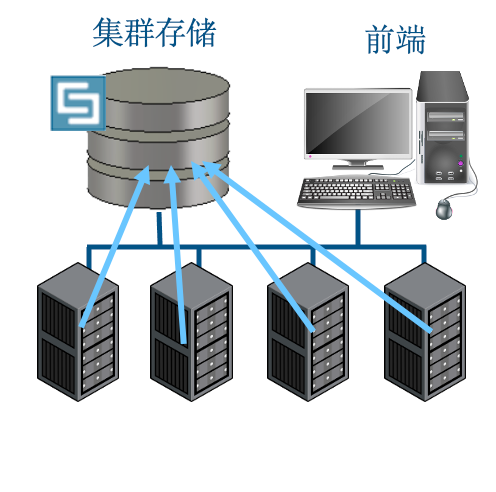
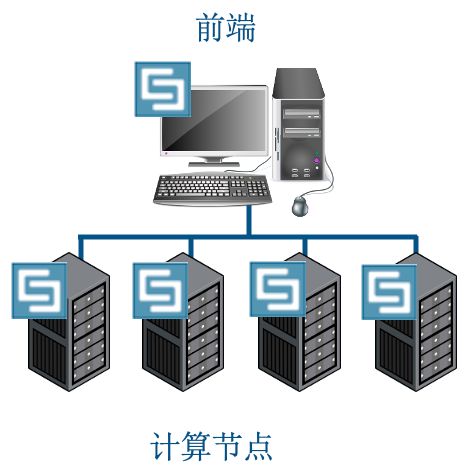
共享存储
CST项目在文件服务器上;无需数据传输















